由于自己的小项目需要后台支持,所以前段时间学习了下 Node.js。简单介绍下 Node.js,Node.js 是一个基于 JavaScript 语言和 V8 引擎运行在服务端的并发平台,在 Node.js 出现以后,使得 JavaScrip 不光能写前端的动态效果,交互效果,还能写 web 服务器,从此,前端工程师的触角向后延伸了一大块。Node.js 功能如此强大,但是我今天才初步学习Node.js,对于一个前端人员来说实在是很惭愧。
一. 页面结构分析
话不多说,正式进入主题。今天我们要抓取的网站是笔者的大学校报(校园资讯),首先我们来简单分析下网站的页面结构。
分页规律:
第一页 http://news.ecjtu.jx.cn/1920/list.htm
第二页:http://news.ecjtu.jx.cn/1920/list2.htm
第三页:http://news.ecjtu.jx.cn/1920/list3.htm
由此可以看出,页面都是以list+page作为分页的。
文章列表页分析:
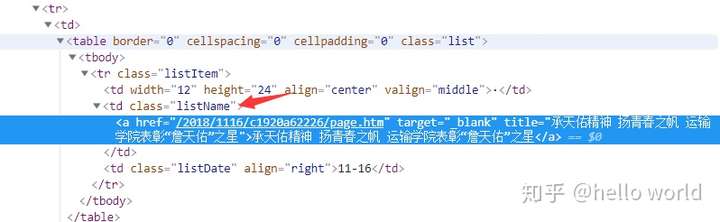
我们可以看到文章列表是以table格式显示的,并且每个class为listName的第一个a标签就是文章详情的入口。
文章详情页分析:

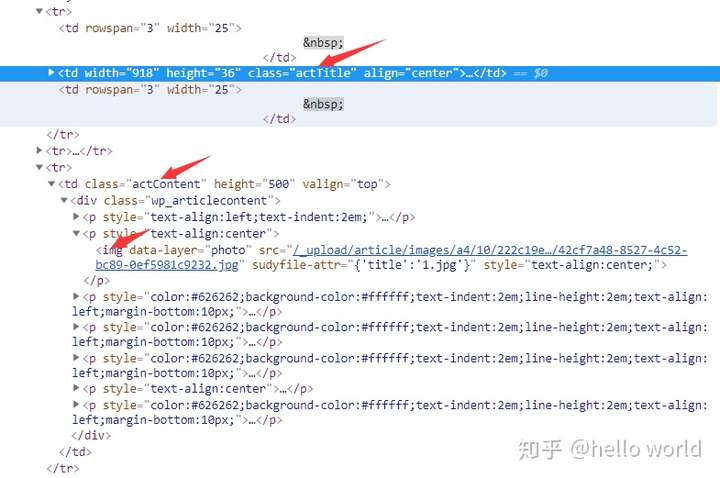
由此可以发现页面规律:
文章标题: .actTitle 文章详情: .postmeta 正文图片:.wp_articlecontent>p>img
浏览次数: .WP_VisitCount
二. 代码编写
在编写代码之前,我们先了解一些需要用到的模块,由于http模块、fs模块都是Node.js内置的包,因此不需要额外添加。
superagent:它是一个强大并且可读性很好的轻量级ajax API,是一个关于HTTP方面的一个库,而且它可以将链式写法玩的出神入化。(这里笔者只是尝试下 superagent 写法,使用http 模块一样效果)
cheerio:可以理解成一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一模一样。
安装这些模块
1
| npm install superagent cheerio url --save
|
完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| const superagent = require('superagent');
const cheerio = require('cheerio');
const async = require('async');
const fs = require('fs');
const url = require('url');
const request = require('request');
const urlHead = 'http://news.ecjtu.jx.cn';
let allUrl = []; // 所有文章连接
let imgUrlList = []; // 图片url
//爬取10页
for(let i = 0; i <= 9; i++) {
// 循环请求文章列表页
requestUrl = 'http://news.ecjtu.jx.cn/1920/list' + i + '.htm';
superagent.get(requestUrl)
.end((err,res) => {
if(err) {
return console.error(error);
}
// cherrio模块获取页面内容
let $ = cheerio.load(res.text);
// 获取文章列表所有链接
$('.listName>a:first-child').each((idx,elem) => {
let $elem = $(elem);
let href = url.resolve(requestUrl,$elem.attr('href'));
allUrl.push(href);
// 文章详情页信息
superagent.get(href)
.end((err,res) => {
if(err) {
return console.error(error);
}
let $ = cheerio.load(res.text);
let _href = href;
// 对文章图片url需处理
let imgUrl = $('.wp_articlecontent>p>img').attr('src') ||
"http://xw.ecjtu.jx.cn/_upload/article/images/c7/89/be9f5e4845c69f6991ad006ab241/f2ba53cf-e7f4-497b-bec8-1b254e2b5f6c.jpg";
// 文章信息
let articleInfo = {
"address": _href,
"title": $('.actTitle').text().trim(),
"detail": $('.postmeta').text().trim(),
"view": $('.WP_VisitCount').text(),
"imgSrc": $('.wp_articlecontent>p>img').attr('src') || "",
}
if( imgUrl.indexOf("http") == -1 ) {
imgUrl = urlHead + imgUrl;
}
imgUrlList.push(imgUrl);
console.log(articleInfo);
console.log(imgUrl)
console.log(imgUrlList);
// 注意有些网站需要设置UA才可以爬取网页内容
const options = {
url: imgUrl,
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
}
// 数据存储在本地文件中
fs.appendFile('data/result.json', JSON.stringify(articleInfo), 'utf-8',(err) => {
if(err) throw new Error("数据存储失败....");
console.log('存储成功!');
})
// 同步存储图片
request.head(options,(err,res,body) => {
if(err) console.log(err);
})
request(options).pipe(fs.createWriteStream('./ecjtuImages/' + (new Date()).getTime() +'.jpg'));
// 异步获取图片需要使用到async异步下载
/*
const downloadPic = (src,dest) => {
request(src).pipe(fs.createWriteStream(dest)).on('close',function(){
console.log('pic saved!')
})
}
async.mapSeries(imgUrlList,function(item, callback){
setTimeout(function(){
downloadPic(item, './ecjtuimages/'+ (new Date()).getTime() +'.jpg');
callback(null, item);
},400);
}, function(err, results){});
*/
})
})
})
}
|
代码中使用了 Node.js 中模块的一些基本用法,有不懂的同学可以看看官网。
我们将爬取的文章信息储存在本地 result.json 文件中,图片储存在 ecjtuimages 文件夹中。
注意:有些网站需要设置User-Agent才能爬取网页信息哦。并且当你需要下载大量图片时,可以使用async模块的mapSeries方法异步下载哦。
三. 运行程序
完成上述两步操作之后,运行 node index.js ,我们可以看到程序开始爬取了。
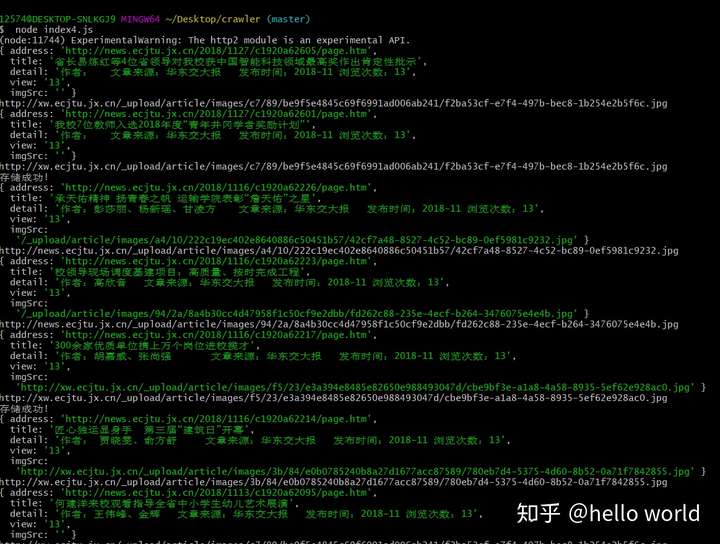
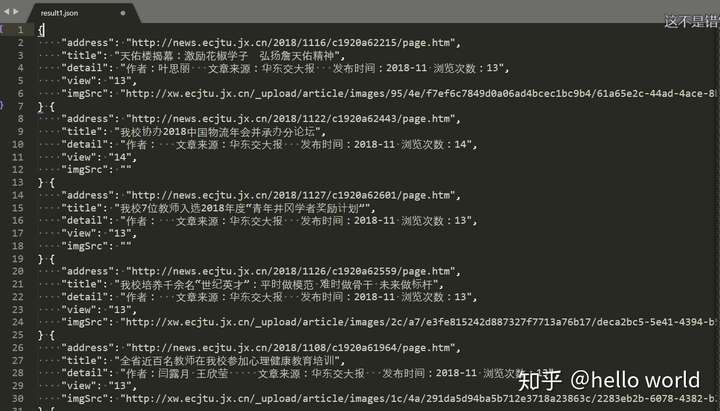
打开 result.json 文件和 ecjtuimages 文件夹查看是否存储成功。

到这里,Node.js 简单的爬取网页数据就结束了。有兴趣的同学也可以引入 mysql,将数据直接存储在数据库中。(笔者私下爬取了很多精彩丰富的内容,欢迎来扰)
总结
此次爬取的网站安全性较差,但有些网站的反爬虫技术做的很好,再使用这种方法就无法爬取了哦。 这次只是简单的 Node.js 初试,仅仅是初探,就已经体会到了 Node.Js 的魅力。更多Node.js 强大的功能我们一起学习。如文章有误之处,欢迎指正。